Introducción a Compiladores y Trasladores
Definición de Compilador
Un compilador es un programa especializado que traduce un programa escrito en un lenguaje de programación de alto nivel (lenguaje fuente) a un lenguaje de bajo nivel, generalmente código máquina o código intermedio, que puede ser ejecutado directamente por una computadora. Los compiladores son fundamentales en el desarrollo de software, ya que permiten que los lenguajes de programación sean utilizados para escribir código en una forma comprensible para los humanos, mientras que la computadora recibe instrucciones específicas y detalladas en un formato que puede ejecutar.
Los lenguajes de alto nivel incluyen lenguajes como C, Java, Python, entre otros, mientras que el código de bajo nivel está más cercano a las instrucciones específicas que el procesador puede entender, como ensamblador o código binario.
Función de un Traductor
Un traductor es cualquier programa que toma como entrada un texto en un lenguaje fuente y genera como salida otro texto en un lenguaje destino. Este término engloba tanto a los compiladores como a los intérpretes.
- Compilador: Traduce todo el código fuente a código máquina o intermedio antes de ser ejecutado. La traducción se realiza de una vez y luego se puede ejecutar repetidamente.
- Intérprete: Traduce y ejecuta el código línea por línea, de manera que la traducción y ejecución ocurren simultáneamente. Los intérpretes son comunes en lenguajes como Python y JavaScript.
Proceso de Compilación
El proceso de compilación es complejo y se realiza en varias etapas. Cada una de estas etapas realiza una tarea específica que, al completarse, transforma el código fuente en un programa ejecutable o en código intermedio. Las etapas principales de un compilador son:
- Análisis Léxico (Lexical Analysis):
- Esta etapa transforma el código fuente en una secuencia de tokens. Un token es una unidad básica del código, como una palabra clave, un identificador, un operador o un literal. El análisis léxico ayuda a simplificar el texto en componentes manejables que el compilador puede procesar.
- Análisis Sintáctico (Parsing):
- En esta etapa, los tokens se organizan en una estructura llamada árbol sintáctico (o árbol de derivación), que sigue las reglas de la gramática del lenguaje fuente. Esta estructura representa la manera en que los componentes del código fuente se relacionan entre sí según la sintaxis del lenguaje.
- Análisis Semántico (Semantic Analysis):
- En el análisis semántico, se verifica que el programa sea correcto desde el punto de vista lógico y que los tipos de datos sean consistentes. Por ejemplo, se chequea que las variables sean utilizadas correctamente según su tipo.
- Generación de Código Intermedio:
- El código fuente es transformado en una representación intermedia que es más fácil de manipular que el código fuente original, pero aún no está en el formato final de ejecución. Un ejemplo de código intermedio es el llamado código de tres direcciones, que divide el programa en instrucciones simples que son más fáciles de optimizar.
- Optimización de Código:
- Esta fase mejora el rendimiento del programa eliminando redundancias, reduciendo el consumo de recursos, y reorganizando el código de manera más eficiente. La optimización puede realizarse a nivel del código intermedio o directamente en el código máquina.
- Generación de Código Máquina:
- En la última etapa, el compilador traduce el código intermedio a código máquina, el cual puede ser ejecutado directamente por el procesador de la computadora. Este código es específico para la arquitectura del hardware en el que el programa va a ser ejecutado.
Diferencias entre Compiladores e Intérpretes
Si bien tanto los compiladores como los intérpretes se utilizan para traducir código de un lenguaje de alto nivel a uno que la máquina pueda entender, hay algunas diferencias clave:
- Compiladores:
- Traduce todo el código antes de ejecutar.
- La ejecución es más rápida ya que el código ya ha sido traducido.
- El proceso de desarrollo puede ser más lento porque el programa completo debe ser recompilado cada vez que se hace un cambio.
- Intérpretes:
- Traduce el código y lo ejecuta línea por línea.
- Es más interactivo y permite probar el código rápidamente sin necesidad de recompilarlo.
- La ejecución suele ser más lenta, ya que la traducción ocurre en tiempo real.
Etapas de un Compilador
- Preprocesador: Se encarga de incluir archivos, expandir macros y eliminar comentarios.
- Analizador Léxico: Convierte el código en tokens.
- Analizador Sintáctico: Organiza los tokens en una estructura jerárquica.
- Generador de Código: Produce el código intermedio o código máquina.
- Optimizador: Mejora el rendimiento del código generado.
- Enlazador (Linker): Junta diferentes módulos de código en un archivo ejecutable completo.
Tipos de Compiladores
Tipos de Compiladores
Proceso de compilación
El proceso de compilación consiste en convertir un programa escrito en un lenguaje de alto nivel a un código ejecutable o código de máquina. Este proceso se divide en dos grandes fases: análisis y síntesis.
Estructuras de datos empleadas en un compilador
Clasificación de compiladores
- Compiladores de una sola pasada: Generan el código de máquina en una única lectura del código fuente.
- Compiladores de varias pasadas: Realizan múltiples lecturas del código fuente antes de generar el código de máquina.
- Compiladores cruzados: Generan código para un sistema diferente del que se está utilizando para el desarrollo.
- Compiladores optimizadores: Realizan modificaciones en el código para mejorar su eficiencia sin alterar la funcionalidad original.
- Compiladores JIT (Just In Time): Compilan partes del código a medida que se necesitan durante la ejecución del programa, combinando aspectos de compilación e interpretación.
- Compiladores incrementales: Generan código objeto instrucción por instrucción a medida que se escribe el código fuente.
- Meta compiladores: Estos programas reciben especificaciones de un lenguaje y generan compiladores para dicho lenguaje.
- Descompiladores: Realizan el proceso inverso a la compilación, convirtiendo código máquina en código de alto nivel.
Herramientas auxiliares del compilador
Enlace al original
- Preprocesador: Se encarga de incluir archivos, expandir macros y eliminar comentarios.
- Linker (Enlazador): Une los diferentes archivos objeto y las bibliotecas para generar el archivo ejecutable.
- Depurador: Permite seguir la ejecución del programa paso a paso para identificar errores.
- Ensamblador: Convierte el código en lenguaje ensamblador a código máquina ejecutable.
Estructura de un compilador
Estructura de un compilador
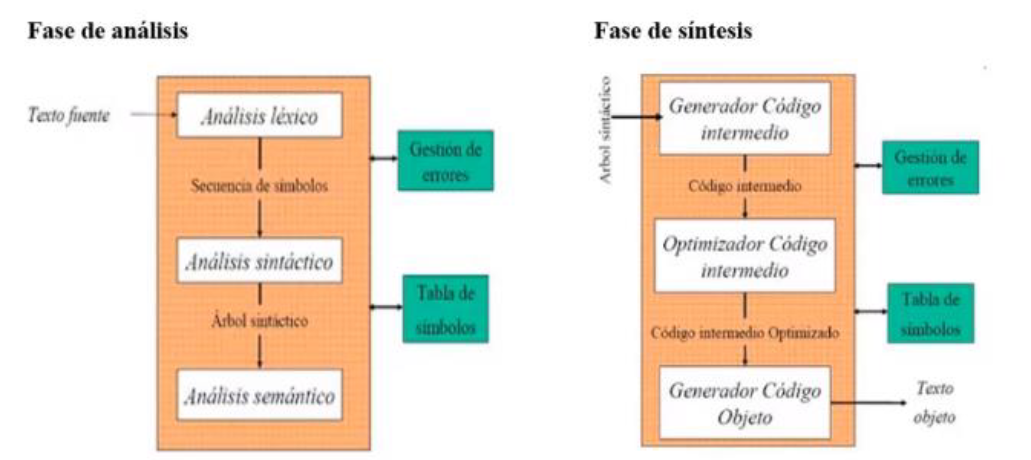
Fase de Análisis
Esta fase se encarga de descomponer y entender el código fuente. Se subdivide en las siguientes etapas:
- Análisis Léxico:
- Esta es la primera etapa del proceso de compilación. El analizador léxico toma el código fuente y lo divide en tokens, que son las unidades básicas del lenguaje, como palabras clave, operadores y delimitadores.
- Propósito: Ayuda a identificar los componentes básicos del código y a eliminar cualquier espacio en blanco, comentarios o caracteres innecesarios.
- Analizador Sintáctico:
- Una vez que se tienen los tokens, el analizador sintáctico organiza estos tokens en una estructura jerárquica llamada árbol sintáctico o árbol de derivación.
- Propósito: Determina cómo se estructuran las construcciones del lenguaje, asegurándose de que la secuencia de tokens siga las reglas gramaticales del lenguaje de programación.
- Backus-Naur Form
- Syntax Diagrams
- Analizador Semántico:
- El analizador semántico revisa el árbol sintáctico para asegurarse de que las construcciones del código tengan sentido dentro del contexto del lenguaje. Esto incluye verificar que las variables estén declaradas antes de ser utilizadas, que los tipos de datos sean consistentes y que las operaciones realizadas sean válidas.
- Propósito: Asegura que el código no solo esté estructurado correctamente, sino que también tenga un significado lógico y correcto dentro del contexto del programa. Por ejemplo, valida el flujo de ejecución y la lógica subyacente.
- Esquemas de traducción de un compilador
- Esquemas canónicos y de traducción
- Analizador Pragmático:
- Esta etapa, menos comúnmente mencionada, considera el contexto de uso del código y cómo interactúa con su entorno de ejecución. El analizador pragmático se enfoca en cómo el código se comportará cuando sea ejecutado, teniendo en cuenta aspectos como la integración con otros sistemas o la interacción con el usuario.
- Propósito: Detecta y maneja situaciones que podrían causar errores en tiempo de ejecución, como el acceso a recursos inexistentes o condiciones no anticipadas durante la ejecución del programa.
Fase de Síntesis
Una vez que el código fuente ha sido completamente analizado y validado, el compilador procede a la fase de síntesis, que consiste en generar el código final que será ejecutado por la máquina.
- Optimización:
- En esta etapa, el compilador mejora la eficiencia del código generado sin alterar su funcionalidad. Esto puede incluir la eliminación de código redundante, la simplificación de expresiones o la reorganización de instrucciones para un mejor rendimiento.
- Propósito: Producir un código más rápido y eficiente, minimizando el uso de recursos.
- Generación de Código:
- Finalmente, el compilador traduce el código intermedio optimizado a código máquina específico para la arquitectura del procesador en la que se ejecutará el programa.
- Propósito: Convertir el código fuente en un formato que pueda ser ejecutado directamente por la máquina.
Tabla de símbolos
La tabla de símbolos es una estructura de datos clave en el proceso de compilación, utilizada durante la fase de análisis léxico, sintáctico y semántico del compilador. Su propósito principal es almacenar y gestionar información sobre los identificadores utilizados en el programa fuente, como variables, funciones, constantes, entre otros. Cada entrada en la tabla de símbolos contiene un identificador y una serie de atributos asociados a él, tales como:
- Nombre del identificador: El nombre exacto que aparece en el código fuente.
- Tipo de dato: El tipo de variable o función, como
int,float,char, etc.- Ámbito (scope): Indica en qué parte del programa es válido el identificador, como una función o un bloque específico.
- Dirección de memoria: La ubicación en la memoria donde se almacenan los valores de las variables.
- Valor: El valor asignado a las constantes o el valor actual de las variables.
- Número de parámetros: Si el identificador es una función, almacena la cantidad de parámetros que recibe.
La tabla de símbolos se actualiza continuamente a lo largo del proceso de compilación. A medida que el compilador va reconociendo nuevos identificadores, los va añadiendo a la tabla con la información correspondiente. Además, se consulta cada vez que es necesario verificar el uso de un identificador en diferentes contextos (como la llamada a funciones o el uso de variables).
Gestor de errores
El gestor de errores es una parte fundamental del compilador que se encarga de detectar y manejar los errores que ocurren durante el proceso de compilación. Los errores pueden ser de diferentes tipos:
Enlace al original
- Errores léxicos: Son errores que ocurren cuando el compilador no puede reconocer una secuencia de caracteres como un componente válido del lenguaje. Por ejemplo, si se utiliza un símbolo no permitido o una palabra clave incorrecta.
- Errores sintácticos: Estos errores suceden cuando la estructura del código fuente no sigue las reglas gramaticales del lenguaje de programación. Un ejemplo es un paréntesis o una llave sin cerrar, o una expresión mal formada.
- Errores semánticos: Estos son errores lógicos que surgen cuando el significado del código es incorrecto o inconsistente con las reglas del lenguaje. Por ejemplo, intentar sumar una cadena de texto con un número, o llamar a una función con un número incorrecto de parámetros.
- Errores de tiempo de enlace (linking errors): Ocurren cuando el enlazador no puede encontrar las definiciones de funciones o variables externas referenciadas en el programa.
- Errores de tiempo de ejecución: Son aquellos que ocurren durante la ejecución del programa, como un acceso a una memoria no válida o una división por cero.
Estructuras de datos empleadas en un compilador
Estructuras de datos empleadas en un compilador
1. Tabla de símbolos
La tabla de símbolos es una estructura fundamental que se utiliza para almacenar información sobre los identificadores presentes en el código fuente, como variables, funciones, constantes y otros elementos. Se actualiza durante el análisis léxico y se consulta a lo largo de las demás fases del compilador.
Datos almacenados en la tabla de símbolos:
- Nombre del identificador
- Tipo de dato (int, float, char, etc.)
- Ámbito o alcance (local, global)
- Dirección de memoria (si es una variable)
- Parámetros (si es una función)
- Cualquier otra información relevante según el lenguaje de programación
Se puede implementar como un árbol de búsqueda binario o una tabla hash para hacer más eficientes las búsquedas y actualizaciones.
2. Árbol sintáctico (Parse Tree)
El árbol sintáctico es una representación jerárquica del código fuente que muestra cómo se estructuran las expresiones y sentencias según las reglas gramaticales del lenguaje. Se genera durante el análisis sintáctico y cada nodo del árbol representa un componente sintáctico.
- Nodos internos: Representan operadores, declaraciones o sentencias.
- Hojas: Representan valores literales, identificadores o constantes.
El árbol sintáctico permite verificar la estructura correcta del programa y facilita el análisis semántico y la generación de código.
3. Árbol sintáctico abstracto (AST - Abstract Syntax Tree)
El árbol sintáctico abstracto (AST) es una versión simplificada del árbol sintáctico que omite los detalles redundantes de la gramática. Se utiliza para representar la estructura lógica del programa de una manera más compacta y directa. En el AST, solo se incluyen los nodos que son esenciales para la generación de código.
Por ejemplo, en una expresión matemática como
a + (b * c), el AST solo incluiría los operadores y operandos, ignorando paréntesis y otros elementos de la gramática.4. Pila de operandos
Durante la generación de código intermedio y la evaluación de expresiones, los compiladores a menudo utilizan una pila de operandos para gestionar la evaluación de expresiones aritméticas y lógicas. Los operandos y resultados intermedios de las operaciones se almacenan temporalmente en esta pila.
Esta estructura es útil en el manejo de expresiones complejas, en particular al convertir expresiones infijas a posfijas (notación polaca inversa), lo que facilita la generación del código de máquina o código intermedio.
5. Tabla de tipos
La tabla de tipos se utiliza para almacenar información sobre los tipos de datos en el programa, especialmente durante el análisis semántico. Permite verificar la compatibilidad de tipos en las expresiones y sentencias.
Datos almacenados:
- Tipos básicos: enteros, flotantes, caracteres, etc.
- Tipos definidos por el usuario: estructuras, clases, etc.
- Reglas de conversión de tipos
La tabla de tipos es clave para detectar errores semánticos, como la asignación de un valor de un tipo incorrecto a una variable.
6. Tabla de constantes
La tabla de constantes es una estructura que almacena todas las constantes literales (números, cadenas, etc.) que aparecen en el programa fuente. Esta estructura permite asignarles direcciones de memoria y reutilizarlas eficientemente durante la ejecución del programa.
Datos almacenados:
- Valor de la constante
- Tipo de la constante
- Dirección en la que se almacena en la memoria
7. Código intermedio
El código intermedio es una representación intermedia del programa, que está entre el código fuente y el código de máquina. A menudo se utiliza una estructura como una lista enlazada o un gráfico de flujo de control para gestionar el orden de ejecución de las instrucciones intermedias.
Las formas comunes de representación del código intermedio incluyen:
- Código de tres direcciones: Cada instrucción tiene un operador y hasta tres operandos. Ejemplo:
x = y + z.- Grafos de flujo de control: Representan el flujo lógico del programa, con nodos que indican bloques de código y aristas que representan saltos condicionales y secuenciales.
8. Pila de llamadas (Call Stack)
La pila de llamadas es utilizada para gestionar las invocaciones a funciones y procedimientos durante la ejecución de un programa. Cuando una función es llamada, se almacena en la pila un registro de activación que contiene información sobre:
- Parámetros pasados a la función
- Valores locales de la función
- Dirección de retorno para continuar la ejecución después de la llamada
Esta estructura permite gestionar el paso de parámetros, el retorno de valores y el control de flujo en las llamadas a funciones y recursiones.
9. Tabla de bloques básicos
La tabla de bloques básicos se utiliza para dividir el programa en secciones o bloques que se ejecutan secuencialmente sin interrupciones (como saltos condicionales o bucles). Esta estructura facilita la optimización del código intermedio y del código de máquina.
Enlace al original